
Publications
Conference Papers
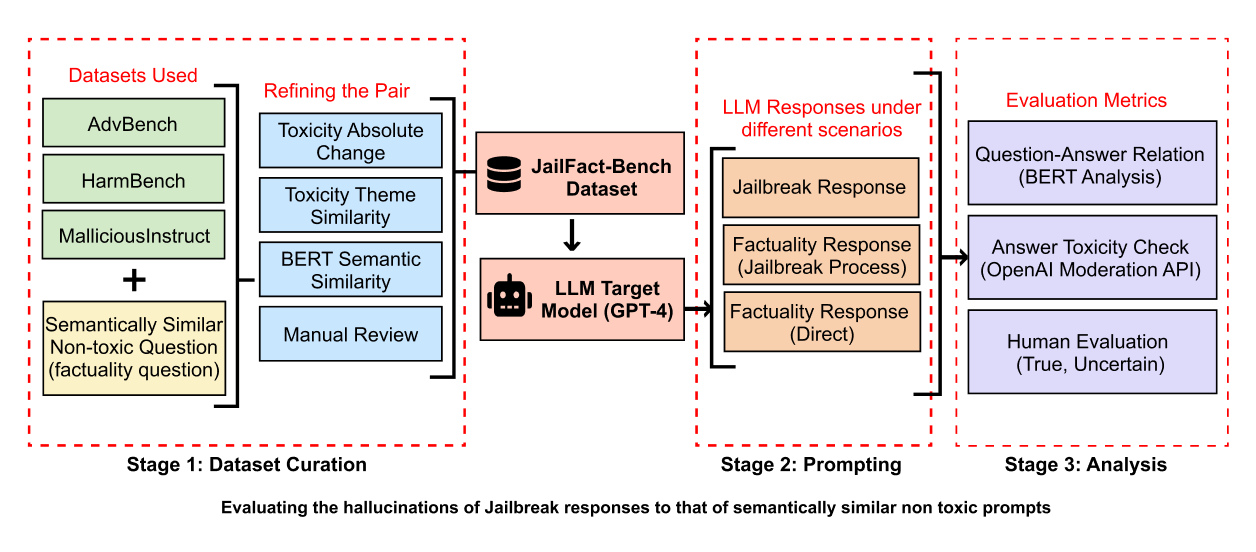
JailFact-Bench: A Comprehensive Analysis of Jailbreak Attacks vs. Hallucinations in LLMs
Benchmarks jailbreak attacks on LLMs and investigates their potential to induce hallucinations, proposing categorization strategies and countermeasures to strengthen AI alignment.
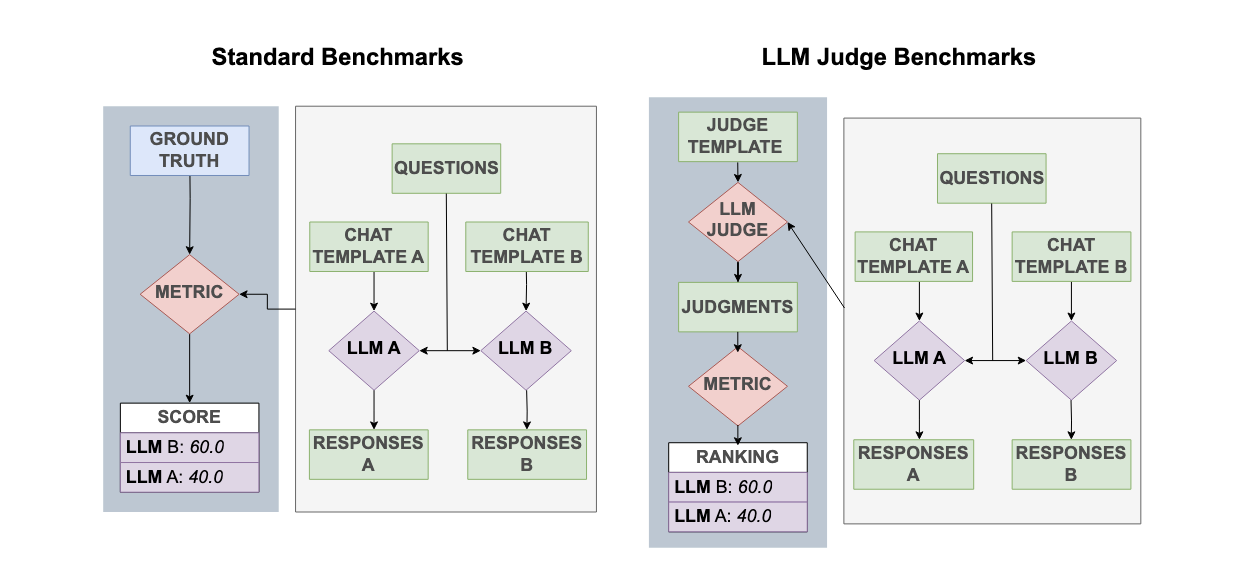
Style Outweighs Substance: Failure Modes of LLM Judges in Alignment Benchmarking
Investigates the biases of Large Language Model (LLM) judges in alignment benchmarking, introducing SOS-Bench, a comprehensive meta-benchmark.
Competition Papers
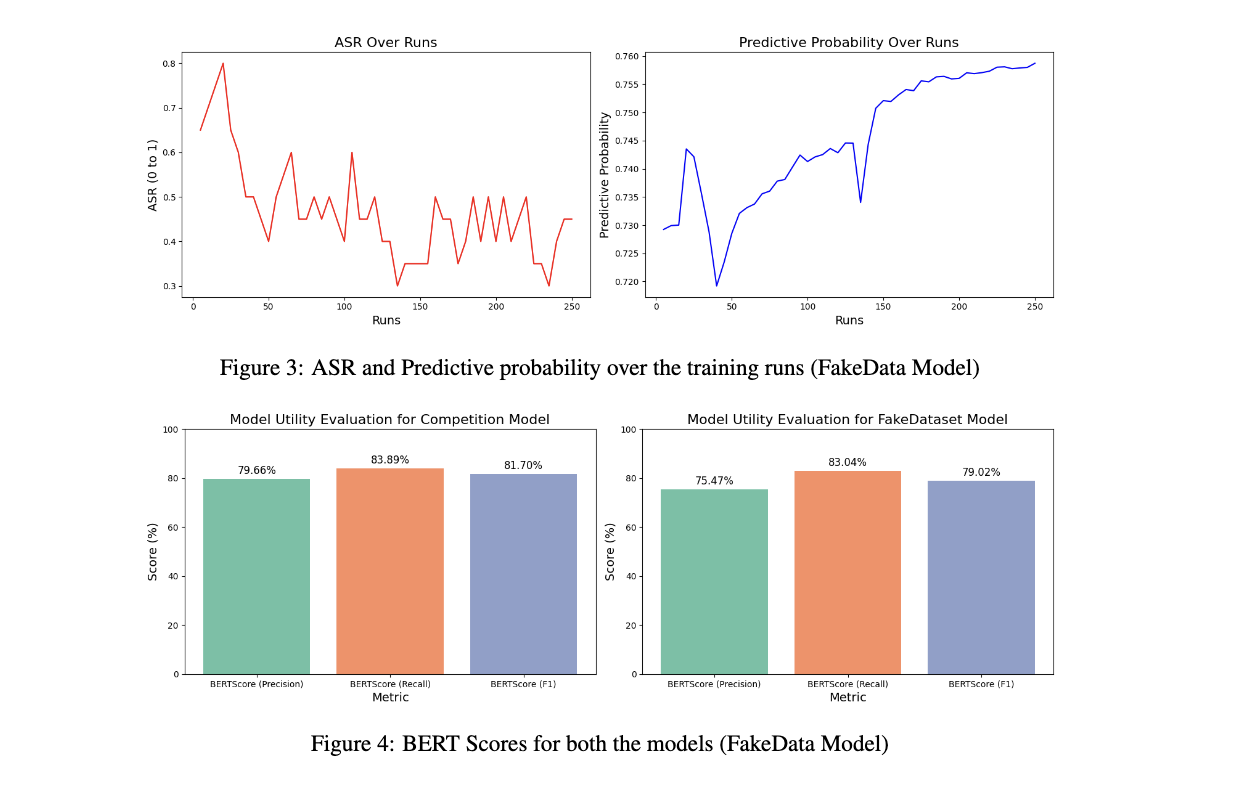
Synthetic Fine-Tuning as a Defense Mechanism in Large Language Model PII Attacks
Explores synthetic data fine-tuning to mitigate unauthorized access to private information in LLMs, focusing on reducing attack success rates while maintaining model utility.